 ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
ʏᴏᴜ ᴀʀᴇ ɴᴏᴛ ʀᴇᴀᴅʏ
building https://next.orly.dev - fast, configurable and scalable relay engine.
telegram: @mleku1
matrix: @mleku17:matrix.org
simplex: https://smp15.simplex.im/a#PPkiqGvf5kZ3AbFWBh3_tw1b_YgvnkSgDEc_-IuuRWc
https://github.com/mleku
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 17:36:18
💕
can't figure out how to extend it tho. but i'll renew it later anyway
⬆
7da2c3aba3ee96c1f63d8b9a4607159d60b7a89e4ae885749fe418a2623bfeea
⬆

Laeserin 🇻🇦
8/23 5:41:34
💕💜 🤙 🤣 🫡
I heard a rumor than nostr.build might be getting kind 20 support and it made me so excited, that I extended my subscription for three more years.
You had to be there. It was a whole... thing.

ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 17:01:46
💕
should just make blossom.nostr.build subdomain and nobody will be confused.
i think #jumble actually says it's nostr.build but that's the only place i think i've seen the two domains next to each other
⬆
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:36:25
💕
yeah, it's confusing but if you open nostr.build without being logged in you see the link up the top bar on the right
⬆
b7b6d2228ee333da5a9497008c9945055dfe7b57e4e34e67b4f88f288598ed5b
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:38:45
💕❤️
it might help to make it more clear that blossom.band is nostr.build property. also, on the page there is no simple way to just copy the link to paste into a client config
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:30:33
💕
or maybe this gets a preview
https://a.nostr.build/vm7a.mp3
⬆
fe27577b844228ef38e342a10a0eed6db43e9f5a0465e93bc76936486ffdb425
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:24:54
💕🎉
proof:

⬆
⬆

⬆
9f3a9a92e73f241f9ec2b5834d983a0cc43d079ab54d40dbf919604fe210f86b
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:05:18
💕
that didn't work either. my npub is broked
⬆

The Fishcake (nostr.build)
8/23 16:03:11
💕
Can you try logging in on a staging stack. staging.nostr.build with code from DM
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:01:50
💕
clicking the link, it up a notification saying: "Error verifying npub"
it doesn't respond correctly when i paste the code from the DM either.
it's not allowing me to log in without a password, and i think that's what the main problem is, and i don't understand why i need a password when i can sign.
⬆
The Fishcake (nostr.build)
8/23 15:57:32
💕
Can you try copy pasting the login code into DM dialog if you are using DM login. Link, technically, supposed to let you in but if it doesn’t work then maybe I have a bug in that area. Extension should work too. If all fails, I’ll reset your password and DM it to you, so you can change it again after login
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 15:54:09
💕
it rejects it with usernpub or password not valid. i can't see what i'm supposed to do with the link it sends me either. i try using that to log in, also doesn't work.
⬆
The Fishcake (nostr.build)
8/23 14:52:17
💕
Should work with extension and DM, try and let me know what errors you see. Tag me if not successful
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 7:53:00
💕
i think blossom works, and blossom.band is the nostr.build blossom server, but i can't log in to notr.build nostr:npub137c5pd8gmhhe0njtsgwjgunc5xjr2vmzvglkgqs5sjeh972gqqxqjak37w because it's been so long i have no idea what my password is, i tried to use the nostr DM login and it just blipped, not working.
wen pure nostr user auth fishcake? am i doing something wrong?
⬆
14a89a4be00985c98dbfdb7b3ed14ff1a52987001eab3b03eadad8cee39faabd
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 16:02:38
💕
well, that's awesome but i was fine with paying, i just want to use the blossom
⬆
The Fishcake (nostr.build)
8/23 16:00:13
💕
I gave you an extra year of subscription on the house, since you abandoned your account almost immediately after initial purchase
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/23 7:56:06
💕
haha what a farce. literally i have to make a new npub to use nostr.build now, i can't even use it if want to, can't even pay to use it.
i hope this is all because it's not making money. maybe raise the price? lol.
i'll stick to text on nostr i think
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
4/4 22:11:59
💕
what android version is that? i have android 13 and that power usage controls stuff is more detailed
⬆
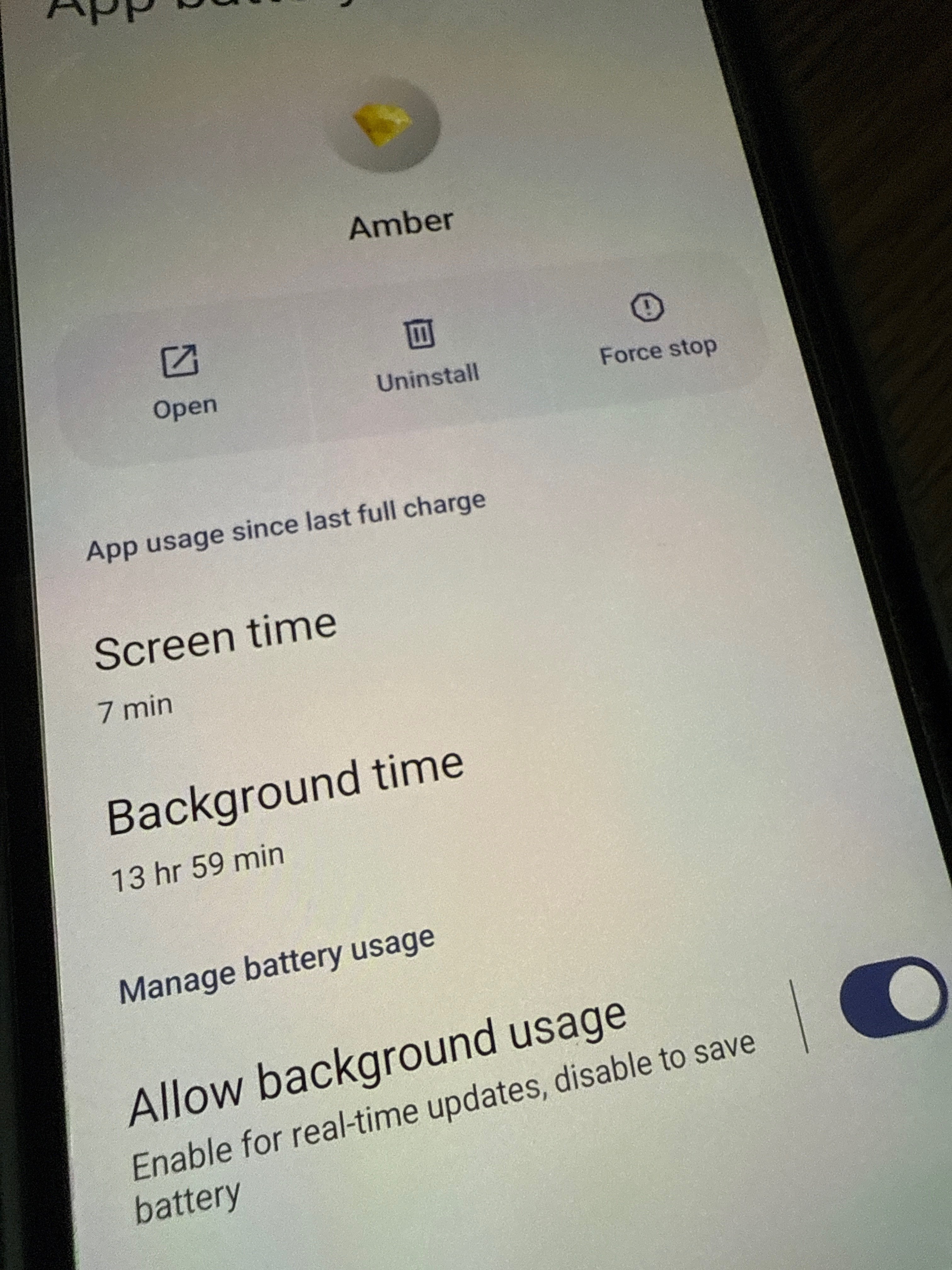
⬆

The Beave
4/4 22:08:06
💕
Check the battery settings on amber. Your OS might be clamping down in background usage.
⬆

Karnage
4/4 22:05:48
💕
I’m not sure. I didn’t do anything differently from other apps. Just installed and opened
⬆
The Beave
4/4 22:02:38
💕
No. That's so weird.
Have you enabled it to work in the background? That's the only thing that I can think of that would stop it from working.
⬆
Karnage
4/4 22:00:25
💕
I’ve never been able to get amethyst working with amber. It just glitches with permissions nonstop and I have no idea how to fix it. Tried reinstalling both apps.
Has anyone had similar issues?
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
3/4 19:11:52
💕
is this a social graph flattened out to 2d? nostr:npub176p7sup477k5738qhxx0hk2n0cty2k5je5uvalzvkvwmw4tltmeqw7vgup you seen this stuff?
⬆

Cody
3/4 18:08:37
💕
Interesting research
nostr:nevent1qvzqqqqqqypzqnza2du6qe3nnjy0dcgpu0kmr7awunk78m4rtl7x78rxfvay8qlwqy88wumn8ghj7mn0wvhxcmmv9uqzqmgw9u0k9nmf532uz2zxwf488y76zhe7kxp9ky3c0l7nevr7l9e5upv0rw
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
1/19 22:58:59
💕
a flurry of discussions and things relating to my work lately have led me to something
there is two current existing query types in nostr, the REQ and the COUNT
REQ has no concrete notion of signalling how many events there are in a request beyond what it has been hard coded to limit results to
COUNT doesn't have metadata to easily determine other than making multiple COUNT queries
"since" and "until" fields in filters can be used to create a boundary that limits the number of results from a REQ but it is inadequate
i could swear i already made this suggestion before
but i'm gonna make it again, if i did, or for the first time if not
there should be a query that just spits back a list of all the event IDs that match a query, and if you set no limit, it just returns the whole set
if you consider that some follow events take as much as 512kb of data, and this is often a common size limit for individual events, then this is good for somewhere around 14000 individual event IDs to be returned in a result, it could be as simple as an array, so overhead is ["<hash>",...]
perhaps this is not sufficient though, maybe you want to include the timestamp next to each event ID... or maybe you could make it so you define the first timestamp of the first event ID, and then after that it's seconds offsets from the previous, this would mean that the list would be something like
[[12345678,"<id>"],[1234,"<id2>"],[2562,"<id3>"], ... ]
i'm inclined to say that fuck the datestamps, i'm just gonna make a new req variant that returns the IDs instead of the results as an array, and to keep with the style, it will just be
["REQID","subscriptionID","<id1>","<id2>", ... ]
the relay already can specify some size limit according to the nip-11 relay information, so it can just stop at just before that size limit and the user can query for that event and get a timestamp "since" to use to get the rest
nostr:npub1ntlexmuxr9q3cp5ju9xh4t6fu3w0myyw32w84lfuw2nyhgxu407qf0m38t what do you think about this idea?
if the query has sufficient reasonable bounds, like, it is very unlikely you want more than 14000 events over a period of let's say, the last day, of a specific kind, and certainly not if you limit it to some set of npubs
but you would still know where the results end, and so long as you stick to the invariant of "this is what i have on hand right now" the question of propagating queries can be capped by the answer of "what i have" and it is implementation internal whether or not you have a second layer and if you then go and cache the results of that query so next time you can send a more complete list
and i am not even considering this option
what about if instead of returning the results encoded in hex (50% versus binary hash size) but instead send them as base64 encoded versions of the event IDs, that gives you 75% or in other words expands the hypothetical max results of just IDs from 14000 to 21000
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
11/24 0:34:36
💕:blobyes:
insurance is a part of the fiat monetary complex though, it's fractional saving, basically... no guarantee you'll ever get back what you put in but you can also get back a lot more than what you put in
i would call that gambling
⬆

halalmoney
11/24 0:27:19
💕🤙
1. You wait until lots of people tell you what to do.
2. And then you say, “You can’t tell me what to do.”
3. Then you go ahead and do what you want.
There is no ‘we’ as I learnt from nostr:npub1fjqqy4a93z5zsjwsfxqhc2764kvykfdyttvldkkkdera8dr78vhsmmleku
⬆

Eric can’t Meme 🐰
11/24 0:20:15
💕
Guys do we buy life insurance or is that gay?
If not gay, who do I give my money to? If gay, I’ll GFM.


ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/11 18:12:12
💕
if i'm logged in, and i pull the entire body of content on the page, and scrape it for the link text prefix, i can get this list
you are talking nonsense, there is code already in the item view that does this, albeit progressively, you just need to pluck that piece out and remove the pagination and attach the action to a button
what will take hours - probably days - is writing a script that does nip-07 auth without being in a web browser
⬆
The Fishcake (nostr.build)
8/11 17:40:42
💕
It is definitely more than an hour of work to make it production ready. Prototype, probably 15min work for me, to production, around a day of work and testing. There are things that should be considered for security. Also, just getting a list of URLs is probably not gonna be useful for 99.9% of people. Ideally, the backup would be a nice downloadable zip file with all of the content, but this is also not an easy thing to implement while avoiding abuse and DDoS vectors (yes we are constantly attacked left and right). I did once asked here if there was an interest in archival storage but demand was 0 🐶🐾🤷♂️
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/11 17:02:27
💕
for a php programmer this is less than an hour's work, please consider the children
⬆
The Fishcake (nostr.build)
8/11 16:38:15
💕
Accepting PRs here: https://github.com/nostrbuild/nostr.build
🐶🐾🫡
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/11 16:35:49
💕
how about you make a simple button that sends the user a text file to download containing all of the URLs of the user's data
i hope you and thet finances of the project are in good health, otherwise i would hate to be you when users lose access to their data
⬆
The Fishcake (nostr.build)
8/11 16:26:35
💕
Make a script to backup notes together with media, problem solved. Same goes for search, technically.
Search will happen, I don’t have time to work on it now, though I already prototyped it at least twice with great results.
It’s all about time, money and priorities. 🐶🐾🫡
⬆
ᴛʜᴇ ᴅᴇᴀᴛʜ ᴏꜰ ᴍʟᴇᴋᴜ
8/11 14:25:45
💕
and they don't have a backup option or any proper search option do you, nostr:nprofile1qythwumn8ghj7un9d3shjtnswf5k6ctv9ehx2ap0qyghwumn8ghj7mn0wd68ytnhd9hx2tcpzamhxue69uhhyetvv9ujumn0wd68ytnzv9hxgtcppemhxue69uhhjctzw5hx6ef0qyg8wumn8ghj7mn0wd68ytnddakj7qg4waehxw309aex2mrp0yhxgctdw4eju6t09uq3jamnwvaz7tmjv4kxz7fwwdhx7un59eek7cmfv9kz7qpq37c5pd8gmhhe0njtsgwjgunc5xjr2vmzvglkgqs5sjeh972gqqxq9u2ntp
⬆

⬆
The Fishcake (nostr.build)
8/11 8:21:06
💕👀 🤙 🤣 🫂
GM! Current state of Nostr in a nutshell 🐶🐾🫡☕️☕️☕️☕️ nostr:note1wnc0wqz6he5dqan58u2v9uccr53fgljtdxpj58653l3mdlz20vaq7l3vg7
